August 18, 2025
8.11-8.17
811-817
上周的主要内容集中在Encodec模块技术路径的可行性实践。
Introduction
- 使用Maestro-v3.0数据集成功复现了Encodec-pyTorch版本的非官方开源代码
- 针对Quantizer中包含的参数: Codebook Size和Codebook Layer Number进行了策略性调整与批量对比实验
- 分析了Codebook容量在重建质量中发挥的作用,并进行了对重建质量影响因素的敏感性分析
- 首次进行四卡并行训练与推理,熟悉了分布式计算的基本规范
- 在实践中掌握了AI生图主流产品的使用流程,并总结了一些有益的经验教训
Main Content
Maestro-v3.0 Dataset
Maestro数据集是一个包含近1300首高质量古典钢琴乐的数据集,总时长两百余小时。数据格式包括.wav/.mid。
相比于之前在进行eeg-music reconstruction任务的脑电信号采集阶段使用的Music stimulus,Maestro数据集显然是一个单曲时长更长,质量更高的选择,也因此对我们模型的重建质量提供了更大的发挥空间。
Encodec-pyTorch
Encodec架构作为Meta发布的一个用于高保真音乐编解码的模型架构,其创新点在于引入了GAN风格的一系列损失函数,并将其通过Balancer模块进行了合理的组合,从而在音乐的时域、频域损失,感知质量,可区分度,量化损失程度等方面进行了综合的约束与引导。其另一创新在于引入了RVQ这一巧妙的量化结构作为进一步压缩量化器体积并减少离散信号冗余度的方法。多层的码本结构类似于一种逐层补偿机制,在逐渐细粒度的量化过程中引导Encoder编码出更容易压缩的Embedding。
对于码本坍塌这一问题,其本质在于编码模态与解码模态间的信息密度差异,或者说码率/带宽的数量级差异。做一道简单的计算题:假如编码模态是以500Hz采样率采样的EEG信号,而解码模态是以22.4kHz/24kHz的音频,那么它们之间的数量级差异就会达到近50倍,而这50倍的信息密度差异足以让我们解码出的音频信号terribly bad。所以,在尽可能保留原始音频结构和保证基本听感的前提下,最大限度地压缩解码模态的码率/带宽是一个显而易见的方式。
于是,我们分别尝试了24kbps/12kbps/6kbps/3kbps/1.5kbps等一系列不同码率的压缩程度,发现在使用3kbps带宽下(也就是4层码本)且每层码本数量为256时,会达到一个不错的trade-off。
SD / MJ
目前业界最主流的AI生图产品无外乎Stable Diffusion(以下简称SD)、MidJourney(以下简称MJ)与DALL $\cdot$ E三剑客,其中我主要想谈的是前两个。
作为开源社区应用最广泛的AI生图工具,SD可以说是有着最广泛的社区支持与源源不断的开发者群体。高度模块化的WebUI界面,众多精细调节的参数选择,即插即用的自定义插件与Adaptor,使得SD拥有了无可比拟的定制化与精细化的生图体验。作为Diffusion、ControlNet等技术路径直接以白盒的方式用于生成式的最好实践,SD在版本不断更新的同时也确实为非专业用户带来了一定的上手门槛。
一方面,高度依赖正负提示词的设计使得编写高质量的英文提示词本身就可以成为一项值得学习的技能;
另一方面,开源项目带来本地部署便利的同时,各种相互独立的效果插件对于存储的占用也成为算力成本之外的另一大开销;
除此之外,调参的复杂化也确实为相对满意的生图效果的复现带来了一些困扰。
这里就不得不谈谈MJ这一alternative了。
作为商业化成熟的闭源平台,MJ在使用渠道上相对受限,无非是Discord和官方Web端,但二者却能很好地互补————Discord中的MJ bot界面简洁,高度命令行式的风格使得用户可以高效地进行批处理,而Web端的可视化与编辑功能完善,方便用户就自己满意的Draft进行派生与微调。
角色一致性问题
- 若人物,使用相机拍出来的照片;若漫画形象,使用网上的原版图片。
- 把1中的图片先交给MJ Discord /Describe 一下
- 然后把1中的图片作为oref放在MJ Web里,并附上2中的text prompt定制出一套动作+姿态+神态组合的character sheet(注意最好一次只专注于一种组合)(无背景,仅人物)
- 从3中的组合库中挑选出自己需要放在场景中的那一种,并作为oref放在MJ Web里,把目标场景作为Image Prompt注入元素,同时作为sref注入风格(注意如果目标场景中的人物神态描述与参考头像神态差异过大,会造成人脸失真等严重问题)
- 若4效果不好,可以先把3通过iOS主体提取作为贴纸(漫画效果有时更佳),然后并通过snapedit把4中生成的图片的主体移除保留背景,然后把贴纸粘贴到背景上再送入3的流程一遍
- 微挑
ps.如何在ow不用设置过高的前提下保持人脸一致性?用一张全身/半身像作为Image Prompt而该角色的人脸像作为oref,ow设置200左右即可
最佳实践
- 效果最好的手动缝合格格不入的人物贴纸之法
首先,先用下图方式塑造目标场景中的目标人物姿势+动作
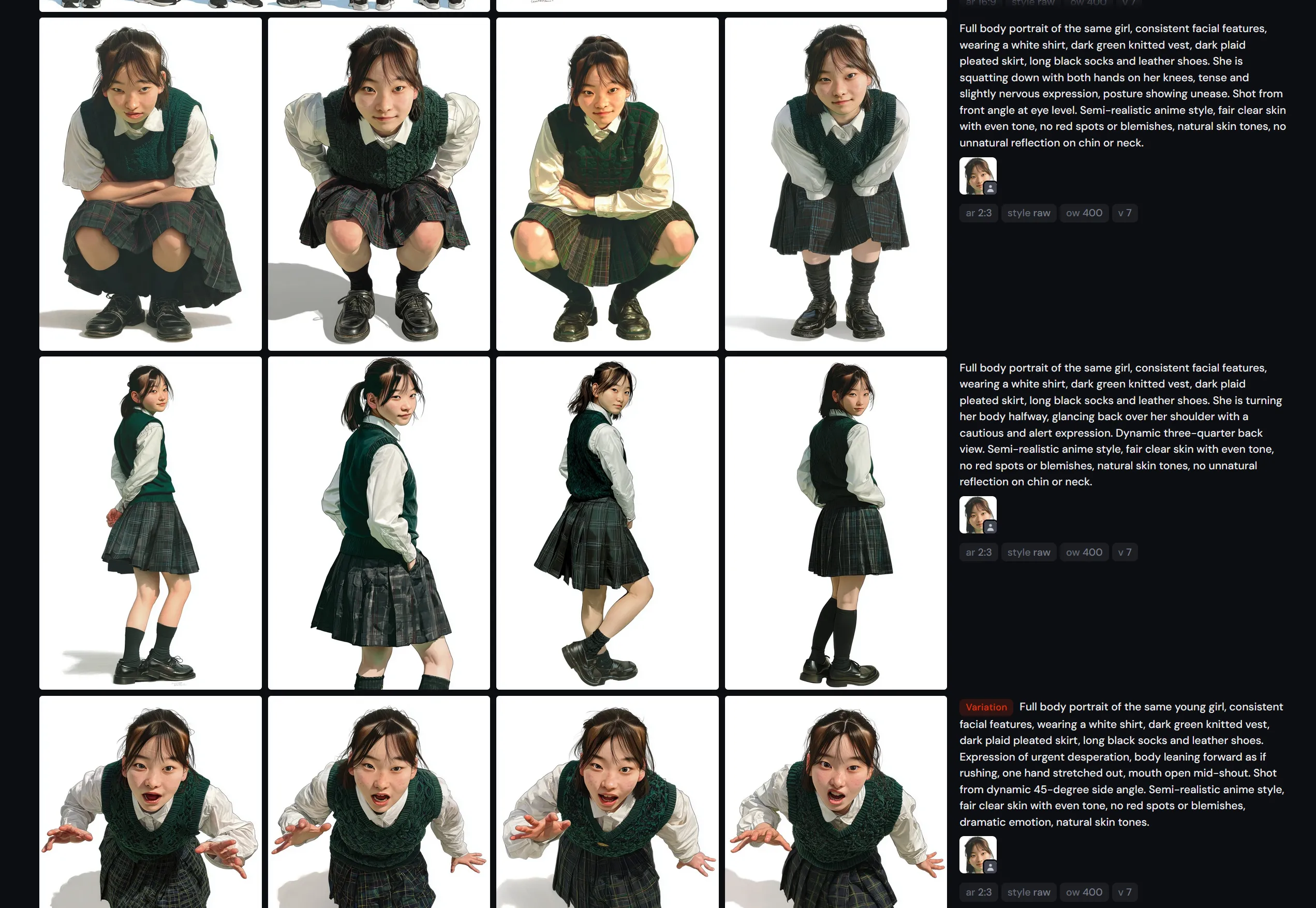 其次,将上一步定制好的漫画风纯人物 / 从之前某张图片中抠出来的人物轮廓(“添加到贴纸”-动态效果之“漫画”)放在Omni Reference选框中(oref weight可以稍微调高一些);
其次,将上一步定制好的漫画风纯人物 / 从之前某张图片中抠出来的人物轮廓(“添加到贴纸”-动态效果之“漫画”)放在Omni Reference选框中(oref weight可以稍微调高一些);
接着,将上述贴纸移动到目标背景上,共同组合成一张新图片,然后放在Image Prompt中;
然后,在Style Reference中放入一张内容语义比较相近的目标缝合效果示意图。
最后,在Text Prompt中输入一句简明的指令: 主-谓-宾即可。(注意比例参数要与Prompt和Reference中的原图接近)

- 效果最好的场景一致性保持方式
同一场景多视角的Image Prompt注入
三维空间扫描/渲染法
之后根据所需视角进行截图即可
-
效果最好的小工具系列
- 智能消除工具: wps会员自带的
- 智能抠图工具: iOS自带的
-
避免色调单一问题
- 在style reference中放入多张风格相似但色调不同、色彩空间覆盖广泛的参考图
- 有时,Image Prompt+合适的文字风格描述本身就能顶替style reference的作用,还不会过拟合
Conclusion
下周的计划是在前期规律及经验总结的基础上,开始正式以eeg信号为出发点的系列实验,采用压缩码本容量的方式去验证减少码本坍塌的可行性。
This post was created using the automated script.